Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 24 Spanish science doesn't need scissors07-Oct-2009Still with the generalized indignation feeling because of the R&D budget cut proposed by the Spanish Government (see Post 22), today lots of Spanish researchers have agreed to post about this misfortune following the initiative La ciencia espanola no necesita tijeras. As it was stated in yesterday's evening news, in the past five years the R&D budget has been one of the main concerns of the Government. This policy has enabled great advances to be achieved in Spain, which in turn has increased the attractiveness to come here for research purposes. If now the policy changes, what's most sensible to believe is that the attractiveness will begin to decrease at alarming rate. It is ridiculous that all the effort this country has made may be crumbled by such a proposal without any great expectations. "If you think that research and education are expensive, try with ignorance and mediocrity." (Joan Guinovart)
 Post 23 Talking RSS Reader for Android05-Oct-2009First, Google is the gold sponsor of Interspeech'09. Then, it releases a speech synthesizer for Google's mobile platform, Android, the Talking RSS Reader. What will be next? It seems that as long as Google is interested in speech technologies, speech processing will be on the rise. Is it good news or not? Post 22 Ridiculous Spanish Government anti-crisis measures threaten R&D budgets30-Sep-2009A few days ago this opinion column appeared in a Spanish newspaper. Its author, Dr. Rodriguez, criticizes the budget cut on R&D that the Spanish Government has proposed to fight the present crisis. Since the column is written in Spanish, I am just going to translate it in this post, please excuse my skewed Spanish constructions.
"R&Desolation Earlier in this blog (see Post 6) Dr. Goldberg already attributed the present scientific wealth of the U.S. to the big budgets that the U.S. Government invested in the universities for research purposes after WW2. Definitely not the way things look here in Spain. Post 21 InterSpeech 2009 Opening Ceremony and Sentiment Classification from Text07-Sep-2009The InterSpeech 2009 conference Opening Ceremony has been held today. Some of the most remarkable scientists that have passed away last year have been rememebered at the beginning of the event. Among them, Dr. Gunnar Fant, who devoted his life to the study of the vocal tract and the measurement of formant values. Afterwards, Dr. Stephen Hawking has given a recorded speech on the importance of speech technologies for the wealth of mankind. Thanks to them, he has been able to communicate his ideas to the world despite of his illness. The ceremony has concluded with a beautiful "All you need is love" (by The Beatles) featured by The Paletine String Quartet. Finally in the afternoon, our work on sentiment classification from text has seen the light! Now the paper is freely available at the Publications section. Post 20 Tutorials Day at InterSpeech 200906-Sep-2009The tutorials before the InterSpeech 2009 conference officially begins (tomorrow) have been held today. In the morning I have attended the "Language and Dialect Recognition" tutorial. This topic wraps the first step on a speech processing pipeline, before a sheer speech recognition engine. It first identifies the language of the speaker and then it spots its dialect. This step permits the use of more refined models for recognition. The tutorial has mostly been focused on acoustics and phonotactics. Following a probabilistic approach, two aspects have surprised me. The first one deals with acoustic features extraction, the Nuisance Attribute Projection (NAP). Instead of modeling the most discriminant features, this approach models the nuisanes that muddy the picture and then removes them from the original space. The second one deals with phonotactics (capturing the constraints in sequences of phonemes). The tutorial showed the importance of this aspect for a language. According to its order (memory), the phonotactics encode an incrediable amount of information. In the afternoon, I have attended the "Statistical Approaches to Dialogue Systems" tutorial. This field deals with modeling dialog acts after being predicted by a speech recognizer and a semantic decoder. Accounting for the errors that these systems may yield, this model makes decisions despite of these uncertainties. Based on tracking via Bayesian belief monitoring and a policy optimization via reinforcement learning, the POMDP framework proposed provides the potential for building robust dialogue systems. By the way, Brighton is a lovely city! ;) Post 19 Long live the robots29-Jul-2009One more year, the CampusBot gathers a huge amount of robotics enthusiasts in Valencia, as part of the CampusParty. I had also once made my first approach to this field, it was my final High School project: WaiterBot. My robot was remotely controlled with a home-made transmitter/receiver pair with a joystick and could carry a glass of e.g. water on a tray without spilling its content. Since it had a couple of orthogonal encoders parallel to its plane of movement it could detect the inclination of the surface it roved and correct this angle with a set of motors and gears. Take a look at the pictures (pic01 and pic02) to see what I mean. Today I thought about that little bot I built eight years ago, it's been a quite a while. I searched my hard drive and recovered the manuscript where the schematics and source code were and put it in my publications space under a Creative Commons license. Eventually that creation is freely available on the Internet. I must say that the waiter robot served me very well in the university. Apart from the knowledge I obtained from hacking with the PIC16F84 microcontroller, which had become very popular among the satellite television cracking community, on my third year at university I replaced the tray device with an ultrasound SONAR and built a RC car which stopped in case of collision danger. The ultrasound SONAR was built with the auto-focusing device of a Polaroid camera, as indicated in the Encoder e-magazine from the Seattle Robotics Society. Its precision allowed the robot to stop at 62cm. from an obstacle. After that, looking forward to completing my Bachelor's degree I set to making a line follower. I had to rebuild the motion mechanism because the gears had worn out. Thus, I replaced the original toy device with a couple of hacked RC boat servo-motors, I dismantled the radio controller and finally attached an array of infrared reflective optical sensors to autonomously drive the robot. I have had a lot of fun with robots after all these experiences. Nowadays there is Arduino, an open-source electronics prototyping platform that is being used not only for robotics, but for many other applications since it has been adopted by many different fields: from art to engineering. It merges free hardware with free software, the best of both worlds ;) It would be great to migrate all academic programs to such open-source frameworks so as to enable/motivate the thorough study of the systems that lay underneath, a goal that cannot be achieved, by definition, with proprietary platforms, be either software or hardware. Post 18 R, Octave and Scilab19-Jun-2009Today the program for the next Jornades de Programari Lliure has been made available on the web portal of this meeting. Although the program is still provisional, the appointed activities schedule a speech on R and a tutorial on Octave and Scilab. As is reported in the description of these events, the speech on R will be focused on the need of these sort of free statistical tools for the wealth of the scientific community. R is presented as a vehicular tool for the collaboration among different research groups, as well as a means of providing students with quality tools to exercise their technical abilities once they attain their grades and leave the university. But I would now like to concentrate on Octave and Scilab since I am somewhat more accustomed to working with them, for convenience. It's wonderful that these tools eventually get to the people. With utilities like these, which are developed and supported by hordes of researchers around the world, I do find it hard to argue in favor of more "traditional" products like Matlab and the like. But the world is still imperfect. I have been using them both for about three years now, dealing with their peculiarities. I will put a clear example to show what I mean. Some days ago, developing a Magnitude Difference Function (MDF) pitch and sonority detector, Scilab resulted 3.63 times faster than Octave (using the same base code). At first sight, one would say that Scilab is a deal better choice: it has a nice GUI, a box diagram based dynamic system simulator and a powerful plotting engine. But when then I developed a LPC vocoder and needed a function to retrieve the LPC coefficients, only Octave provided such function, which means that either the previous code had to be recoded into Octave or that the function had to be recoded into Scilab. To my mind, this is not a big problem, because in any case one ends up learning a lot more than what one was supposed to learn at the beginning of the work, and at the end of it, one has the chance to contribute to the wealth of the software of choice and the scientific community as a whole. Post 17 InterSpeech 2009 conference16-Jun-2009Good news. Our work on sentiment classification from sentence-level annotations of emotions regarding models of affect has been selected for poster presentation at the InterSpeech 2009 conference in a session "Prosody, Text Analysis, and Multilingual Models". The conference will be held on September at Brighton, U.K. Post 16 HMMs considering multiple observations06-Jun-2009The original definition of the (discrete) Hidden Markov Models (HMM) in the speech recognition field [Rabiner, 1989], available here, deals with a single symbol sequence, which implies that the models are shown one single aspect of the speech signal (the spectral behavior features). Thus the models are limited to making predictions based on the features of a speech frame, which is previously framed in time in order to take it for a stationary signal. But speech is by definition a non-stationary time-varying signal (phonemes...), therefore the stationarity assumption is not actually true, but we assume it for simplification. HMMs are meant to model dynamic systems, then it makes little sense not to consider these dynamic features inherent in the signal. The basic idea behind the "multiple observations" concept is that the HMMs in question take into account several observations (discrete symbol sequences) when dealing with data. These additional symbol sequences are extracted from the quantized derivatives and double-derivatives of the speech feature parameters (the velocities and accelerations of these feature parameters). Then enabling the HMMs to deal with this time-varying information they ought to be more accurate in their predictions, and therefore, the HMMs should be able to better predict the behavior of the dynamic system they intend to model.
In order to accomplish this improvement, the HMMs have to track the evolution
of these three discrete symbolic spaces: the coefficients (C), the velocities/deltas (D) and the
accelerations/double-deltas (DD). From now on, the HMMs should be defined with this
consideration, as is shown below: 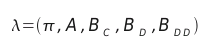
Then, each time the models shall provide the probability of observing the particular symbol triad 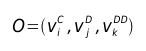 we assume statistical independence between these three spaces for simplicity and redefine the observation probability function for a given state m as: 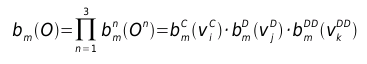 This new observation probability function enables the HMMs to deal with multiple observations. One must bear in mind that in order to reestimate this function in the Baum- Welch procedure, the resulting probability must update all the matrices that define the feature spaces according to the observed symbols. With the inclusion of multiple observations into the HMMs, the performance improvement (Word Error Rate) obtained with the datasets provided in the Speech Processing subject at UPC oscillates between 72% and 53% when testing with the training dataset or with another dataset respectively, reaching an absolute WER of 1.11% in the first case and 7.03% in the second one. Note that these figures have been computed using LPCCs. With MFCCs they even got down to 0.74% and 5.07% respectively. Bearing in mind that this technology is more than ten years old, it's simply fantastic.
-- Post 15 Thank you, Guadalinex19-May-2009The Guadalinex GNU/Linux distribution is one of the most ambitious free software projects in Spain, promoted by the Government of Andalusia (Junta de Andalucia), aimed at spreading the FLOSS culture in the educational sector. This exemplar project deserves my admiration for the technical quality of the distro, the organization of the project and the nice community that supports it. Last year on the 10th of December I could participate in the virtual meeting of collaborators of Guadalinex with my Master's Thesis, the Magnus project in Spanish, a speech recognition application coded in Java for controlling the mouse of the computer (especially important for physically impaired people). The meeting was held through Gobby (a useful tool I had not heard of before) and the experience was very gratifying. We could discuss some of the features the project still lacks, like speaker adaptation (the Andalusian accent is pretty different from the Catalan, which was the seminal implemented language), the flexibility of the application and the performance of a Java app compared to a natively compiled application. And today I have received a sweet present from the Guadalinex team: a Guadalinex penguin mascot toy. They had no reason to do it, but they chose to do so, and I now choose to put it flat-out: the Gualinex project is a great deal more than a mere big free software project. Thank you, Guadalinex. newer | older - RSS - Search |
All contents © Alexandre Trilla 2008-2026 |
{kind=link}
{kind=link}
{kind=link}