Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 16 HMMs considering multiple observations06-Jun-2009The original definition of the (discrete) Hidden Markov Models (HMM) in the speech recognition field [Rabiner, 1989], available here, deals with a single symbol sequence, which implies that the models are shown one single aspect of the speech signal (the spectral behavior features). Thus the models are limited to making predictions based on the features of a speech frame, which is previously framed in time in order to take it for a stationary signal. But speech is by definition a non-stationary time-varying signal (phonemes...), therefore the stationarity assumption is not actually true, but we assume it for simplification. HMMs are meant to model dynamic systems, then it makes little sense not to consider these dynamic features inherent in the signal. The basic idea behind the "multiple observations" concept is that the HMMs in question take into account several observations (discrete symbol sequences) when dealing with data. These additional symbol sequences are extracted from the quantized derivatives and double-derivatives of the speech feature parameters (the velocities and accelerations of these feature parameters). Then enabling the HMMs to deal with this time-varying information they ought to be more accurate in their predictions, and therefore, the HMMs should be able to better predict the behavior of the dynamic system they intend to model.
In order to accomplish this improvement, the HMMs have to track the evolution
of these three discrete symbolic spaces: the coefficients (C), the velocities/deltas (D) and the
accelerations/double-deltas (DD). From now on, the HMMs should be defined with this
consideration, as is shown below: 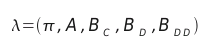
Then, each time the models shall provide the probability of observing the particular symbol triad 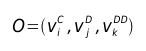 we assume statistical independence between these three spaces for simplicity and redefine the observation probability function for a given state m as: 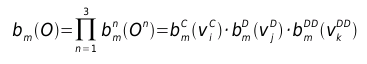 This new observation probability function enables the HMMs to deal with multiple observations. One must bear in mind that in order to reestimate this function in the Baum- Welch procedure, the resulting probability must update all the matrices that define the feature spaces according to the observed symbols. With the inclusion of multiple observations into the HMMs, the performance improvement (Word Error Rate) obtained with the datasets provided in the Speech Processing subject at UPC oscillates between 72% and 53% when testing with the training dataset or with another dataset respectively, reaching an absolute WER of 1.11% in the first case and 7.03% in the second one. Note that these figures have been computed using LPCCs. With MFCCs they even got down to 0.74% and 5.07% respectively. Bearing in mind that this technology is more than ten years old, it's simply fantastic.
-- |
All contents © Alexandre Trilla 2008-2026 |