Blog-- Thoughts on data analysis, software development and innovation management. Comments are welcome Post 42 Information Retrieval techniques in ASR28-Nov-2010I also wanted to blog about Dr. Alex Acero's speech in the FALA 2010 conference. His talk was entitled "New Machine Learning approaches to Speech Recognition", and in brief (quoting his own description), he described some new approaches to Automatic Speech Recognition (ASR) that leverage large amounts of data using techniques from Information Retrieval (IR) and Machine Learning.
The "large amounts of data" detail of the description was in fact the gist of
his work. He recalled that Hidden Markov Model based ASR in the late 60's and
early 70's needed to compress a lot the acoustic features because otherwise
they could not succeed, due to computation capabilities. But today,
some of those assumptions may be challenged. In this regard, he presented
a novel ASR approach where the linguistic models were replaced by an IR
engine based on a Vector Space Model (VSM): 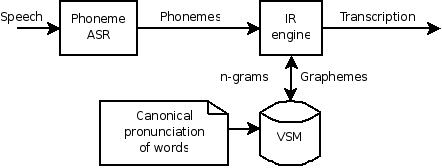 Dr. Acero conjectured that this approach works well if sufficient repetitions per word are available. Hence, by dealing with a huge amount of information, the system is supposed to deliver to a good performance, with an argued robustness to deal with disfluencies. Nevertheless, this novel approach (1) does not still solve the problems with homophony, and (2) gets confused with phoneme/syllable permutations. On the one hand, the classic indetermination with homophones persists at the phrase-level (e.g. the mondegreens) but also at the word-level (have some fun testing an ASR system with a list of words with similar Soundex indexes). On the other hand, the approach is weak toward disambiguating words with rearranged phonemes, e.g., "stop" and "spot" (regarding phonotactic rules in the rearrangement). And I know I'm being fussy here, because in a limited-domain scenario, this approach has actually yielded excellent results. So, although the linguistic knowledge of a speech-enabled application like ASR may not be directly replaceable in general, I find it is a most interesting work to approach different scientific disciplines, avoiding the idealisation of some particular method. |
All contents © Alexandre Trilla 2008-2026 |